Why Build a Data Warehouse
Last modified: October 29, 2019 • Reading Time: 5 minutes
What is a Data Warehouse?
A Data Warehouse (also commonly called a single source of truth) is a clean, organized, single representation of your data. Sometimes it’s a completely different data source, but increasingly it’s structured virtually, as a schema of views on top of an existing lake.

Having a clean unified source of truth enables you to write simpler queries, make fewer errors, work faster (as you’re more organized), and repeat yourself much less often.
This stage is right for you if:
- More than a few people are going to be working with this dataset
- You want a clean source of truth of your company
- You don’t like fighting integrity issues
- You need to separate the structure of the data from the always changing transactional sources.
- You Don’t like Repeating Yourself (DRY)
You’ve outgrown this stage if:
- You want to get democratized - and enable others in your company to explore and understand data themselves
- You’re prepared to teach and enable business users in your company - hopefully using the many resources of the Data School
- You have projects that require different formats of the source of truth for easier use
- Having truly informed employees is important to your company’s competitive success
Six reasons to build a Data Warehouse
- Easier to understand and query - simplified single model. No more duplicate tables, confusing column names, or mysterious values.
- Faster for the data team to use. Less time is needed to clean and transform data to perform analysis.
- Approachable to work with for business users. Complex joins have been reduced and the correct column is obvious.
- Trusted, consistent source of answers. Everyone generates insights from the same data; no more varying answers to the same question.
- Maintainable with less time and effort. After adopting naming conventions and a style guide you can maintain as you add data.
- Separated from transactional data schema. Queries don’t affect app performance, and aren’t affected by rapid changes in the data.
This section of the Data Governance book will explain why you should create a Data Warehouse, and how to implement it so that you get all the benefits it can deliver to your business. Before we dive in deep, let’s look at the data issues you face with a Data Lake.
The Problem with Data Lakes
Typically, organizations reach roadblocks in making sense of the data in their Data Lake. When the amount of data in your Data Lake reaches a level of complexity with irrelevant, unstructured data, it will be too confusing and messy for non-data analysts to use. Data is inconsistent and unstructured, so it can be error-prone with users using the wrong columns or calculating metrics incorrectly.
When organizations have an initiative to empower users outside of the data science or engineering team to leverage data, they will move to a Data Warehouse. What differentiates a Data Warehouse from a Data Lake, or other source, is that the Data Warehouse will provide a cleaner view of the data and is easier for users to query.
To illustrate the difference, imagine all of your inventory is under one roof, but in a big pile. It’s unsorted, and some of it’s rotten. You may know where everything is in the pile, but if you want to work with others you’ll need to organize it. A proper warehouse requires shelves and organization that makes sense to anyone using it.
Take an example of a database tracking a product’s users and usage data. The raw data may be difficult to understand for the average user because of things such as bad naming conventions, complex data types, data inconsistencies, irrelevant data and highly normalized tables.
Example Data Lake Schema:
![]()
This example was designed as a transactional schema, not for analysis. Without a tool such as Chartio, navigating this schema for analysis would be incredibly challenging. However with Chartio you only need to focus on cleaning up tables to get much more value out of your data. Focus on making Data Lake tables easy to understand.
Example Data Lake table:
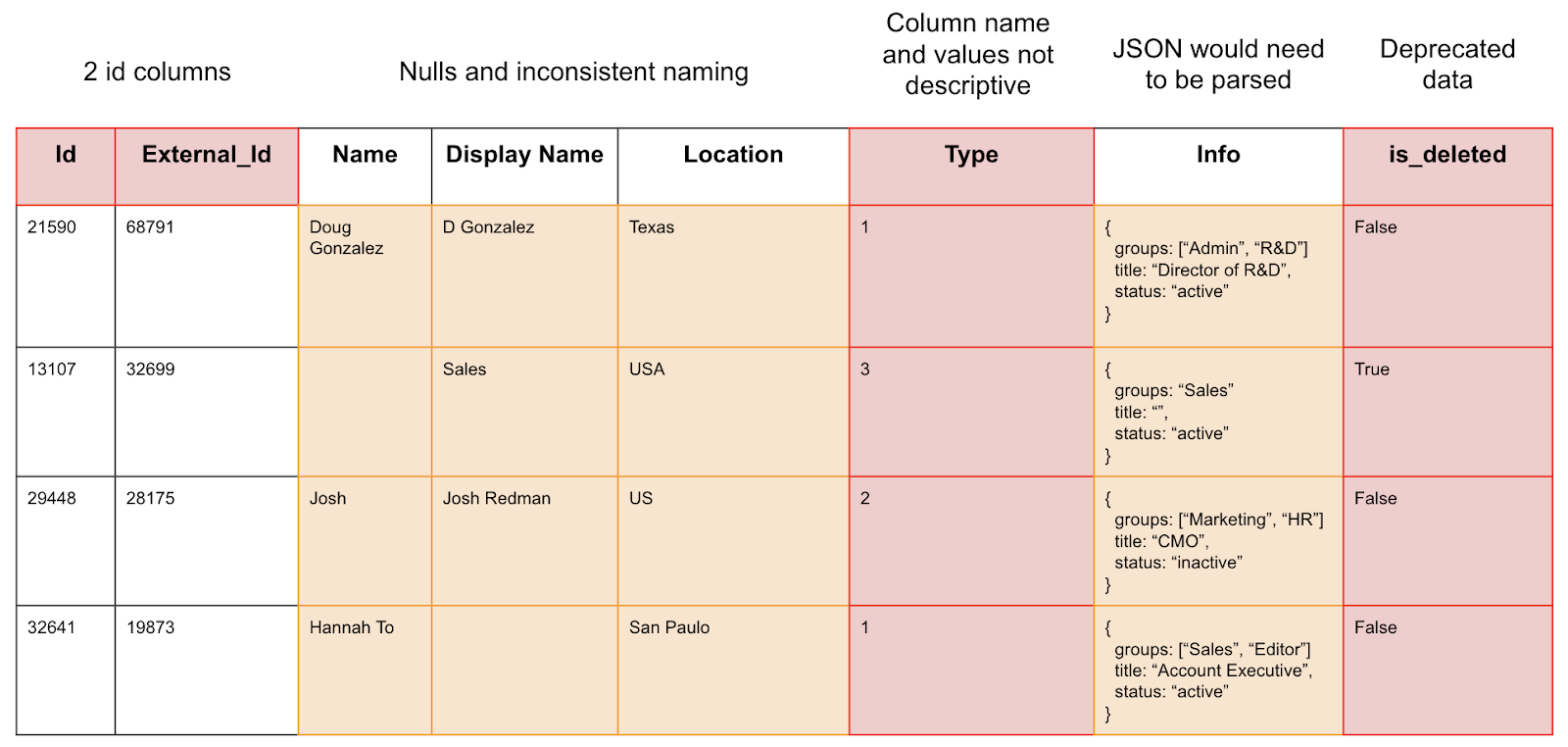
We can see multiple columns with issues that would be difficult for an analyst to understand or make use of. Let’s see how this table could be reconfigured to become useful for analytics.
How Data Warehouses differ from Data Lakes
Use modeling to create a clean version of the schema where all of the above inconsistencies and points of confusion are addressed. This will be your company’s Data Warehouse. It will enable more users to understand and use the data. You can remove a few irrelevant tables for analysis but most of the focus should be on cleaning up columns.
Let’s take the table above and apply some simple transformations to it.
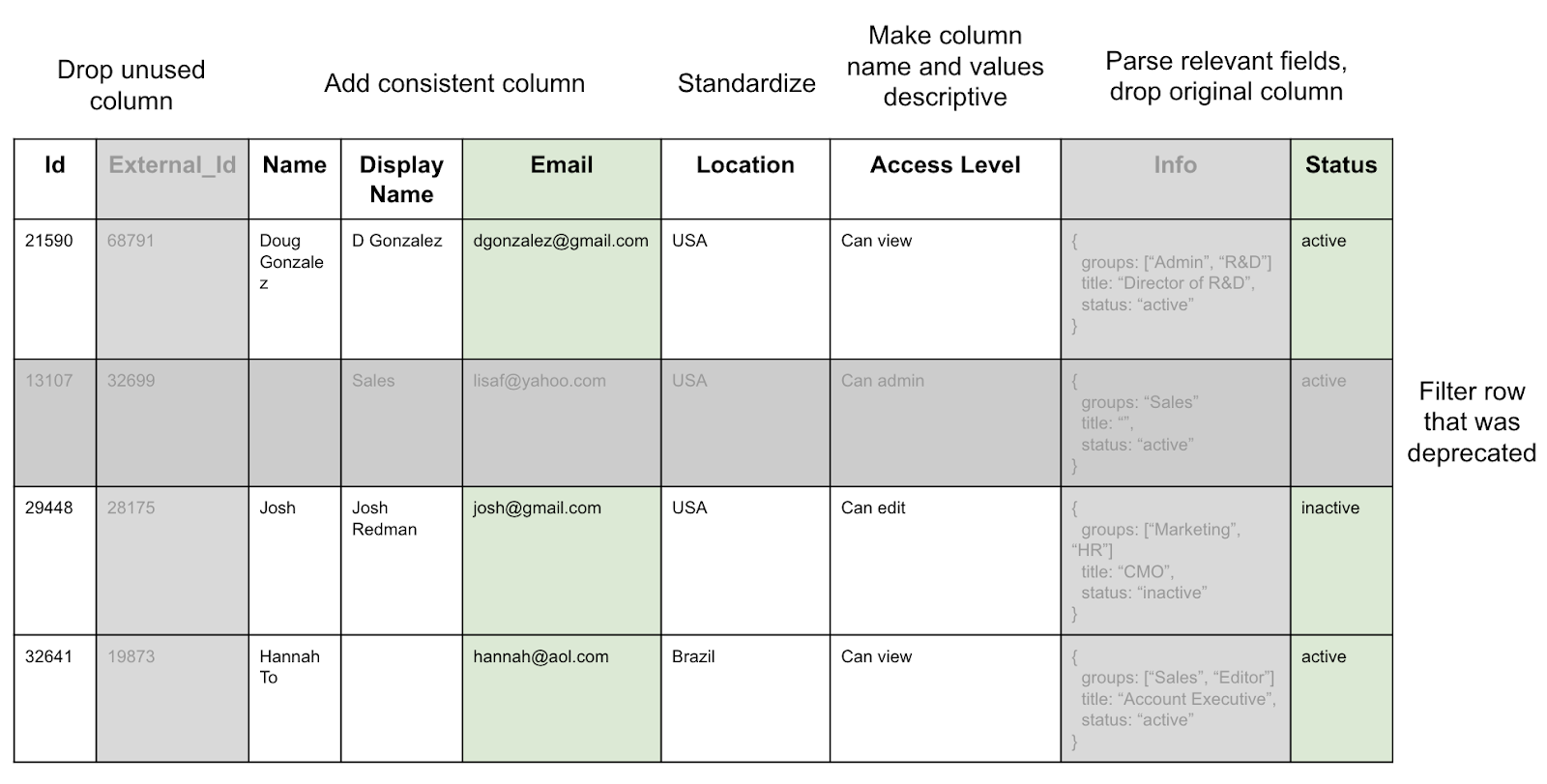
We can see how dropping columns, adding columns, filtering rows and clarifying columns make the data much more straightforward to use and interpret. Now, people without experience with the data have a much easier time coming up to speed and will make fewer mistakes. Let’s look at the final table without all the editing markup.

This is the promise of a Data Warehouse: clear tables that can be used by anyone without having to dramatically alter the schema.
Summary
Data warehouses make your data:
- Easier to understand and query - simplified single model
- Faster for the data team to use
- Approachable to work with for Business Users
- Trusted, consistent source of answers
- Easier and less timely to maintain
Data Lake data is the pile of products in your building.
Data Warehouse is those same products sorted, shelved, and tagged.
Written by:
Tracy Chow
Reviewed by:
Matt David