Introduction - The 4 Stages of Data Sophistication
Last modified: December 19, 2019 • Reading Time: 4 minutes
Modern companies run on and compete with data. Historically businesses had all of the information they needed walking in and out of their store every day. When customers had requests, frustrations, or buying patterns - the owners and employees were there to ask about them and to directly observe trends.
Over time, companies scaled and most people now work for larger, distributed organizations. We’ve grown from single shop businesses, to having many locations, and even to having no location at all. The result is that decision makers no longer have direct access to each customer, and must increasingly rely on their data to improve and compete.
Companies today are quite good at collecting data - but still very poor at organizing and learning from it. Setting up a proper Data Governance organization, workflow, tools, and an effective data stack are essential tasks if a business wants to gain from it’s information.
This book is for organizations of all sizes that want to build the right data stack for them - one that is both practical and enables them to be as informed as possible. It is a continually improving community driven book teaching modern data governance techniques for companies at different levels of data sophistication. In it we will progresses from the starting setup of a new startup to a mature data driven enterprise covering architectures, tools, team organizations, common pitfalls and best practices as data needs expand.
The structure and original chapters of this book were written by the leadership and Data Advisor teams at Chartio, sharing our experiences working with hundreds of companies over the past decade. Here we’ve compiled our learnings and open sourced them in a free, open book.
The 4 Stages of Data Sophistication
From our experience working with so many organizations we recognized four distinct stages of data sophistication that successful companies go through. These stages happen to be tied to a new piece of the data stack that is needed at each stage, and so we have named these stages after those pieces.
This book is organized in sections covering each of these 4 sequential:
- Source
- Lake
- Warehouse
- Mart
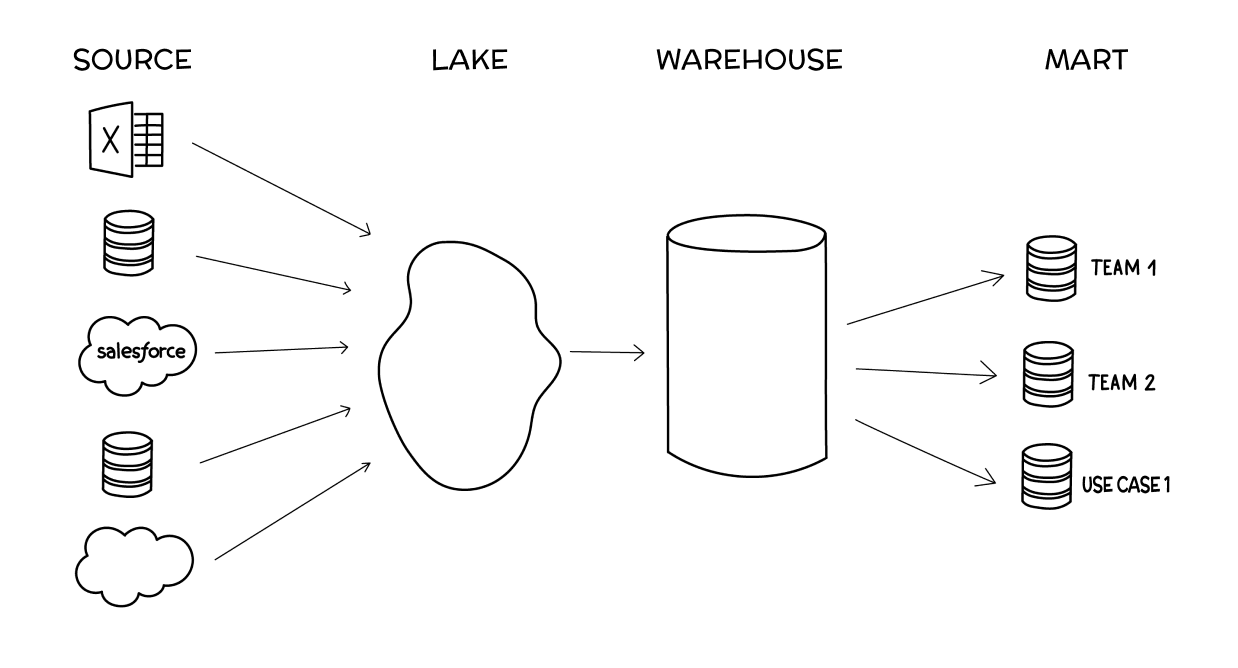
Each vertical stage pictured is a valid stack to operate from, depending on your resources, size, importance and needs of data within your organization. Each has unique benefits, pitfalls and best practices that we’ll cover stage by stage.
Your company may not yet need the entirety of this book, but as a growing company’s data needs expand, it will be incredibly valuable — and perhaps pivotal — to advance all the way through each of these stages to the Mart stage.
We’ll start with an overview of each:
Stage 1. Sources
.png "Source Data")
When you start working with data, you may only have a few sources of interest. Two common early sources are Google Analytics and your application data in whatever PostgreSQL or MySQL database your product runs on. If only a few people at your company need to work with these sources, you might set them up with direct access; it’s more simple and agile for them to just work with the data directly.
Stage 2. Lake
As you start to rely on more data sources, and more frequently need to blend your data, you’ll want to build out a Data Lake—a spot for all of your data to exist together in a unified, performant source.
.png "Data Lake")
Especially when you need to work with data from applications like Salesforce, Hubspot, Jira, and Zendesk, you’ll want to create a single home for this data so you can access all of it together and with a single SQL syntax, rather than many different APIs.
Stage 3. Warehouse (Single Source of Truth)
In the Lake stage, as you bring in more people to work with the data, you have to explain to them the oddities of each schema, what data is where, and what special criteria you need to filter by in each of the tables to get the proper results. This becomes a lot of work, and will leave you frequently fighting integrity issues. Eventually, you’ll want to start cleaning your data into a single, clean source of truth.

This stage—creating a data Warehouse—has historically been quite a nightmare, and there are many books written on how best to model your data for analytical processing. But these days it’s not that hard—and will not only spare you from having to explain all of your schemas’ oddities to new team members, but will also save you as an individual time in having to repeat, edit and maintain your own messy queries.
Stage 4. Marts
When you have clean data and a good BI product on top of it, you should start noticing that many people within your company are able to answer their own questions, and more and more people are getting involved. This is great news: your company is getting increasingly informed, and the business and productivity results should be showing. You’re also less worried about integrity issues because you’ve modeled the data, and you’re continually maintaining it to be a clean, clear source of truth.
Eventually, however, you’ll have hundreds of tables in that source of truth, and users will become overwhelmed when trying to find the data that’s relevant to them. You may also discover that, depending on the team, department, or use case, different people want to use the same data structured in different ways. For these reasons, you’ll want to start rolling out Data Marts.

Data Marts are smaller, more specific sources of truth for a team or topic of investigation. For example, the Sales team may only need 12 or so tables from the main Warehouse, while the Marketing team may need 20 tables—some of them the same, but some different.
Written by:
Dave Fowler
Reviewed by:
Matt David