Snowflake Optimization
Last modified: December 09, 2019
Snowflake is a cloud-based elastic data warehouse or Relational Database Management System (RDBMS). It is a run using Amazon Amazon Simple Storage Service (S3) for storage and is optimized for high speed on data of any size.
The amount of computation you have access to is also completely modifiable meaning that, if you want to run a computationally intense set of queries, you can upgrade the amount of resources you have access to, run the queries, and lower the amount of resources you have access to after. The amount of money that you are charged is dependent on what you use. It has many features to help deliver the best product for a low price.
What is Snowflake and how does it Work?
In SQL there are two main database types:
- Databases for Online Transaction Processing (OLTP):
- These are optimized for retrieving a single row or small amount of rows.
- Uses Row Store
- Databases for Online Analytical Processing (OLAP):
- These are optimized for the performance of analyses like aggregations.
- Uses Column Store
Snowflake is designed to be an OLAP database system. One of snowflake’s signature features is its separation of storage and processing:
- Storage is handled by Amazon S3. The data is stored in Amazon servers that are then accessed and used for analytics by processing nodes.
- Processing nodes are nodes that take in a problem and return the solution. These nodes are grouped into clusters.
The cluster uses MPP (massively parallel processing) to compute any task that it is given. MPP is where the task is given to the cluster’s lead node, which divides the task up into many smaller tasks which are then sent out to processing nodes. The nodes each solve their portion of the task. These portions are then pulled together by the lead node to create the full solution:
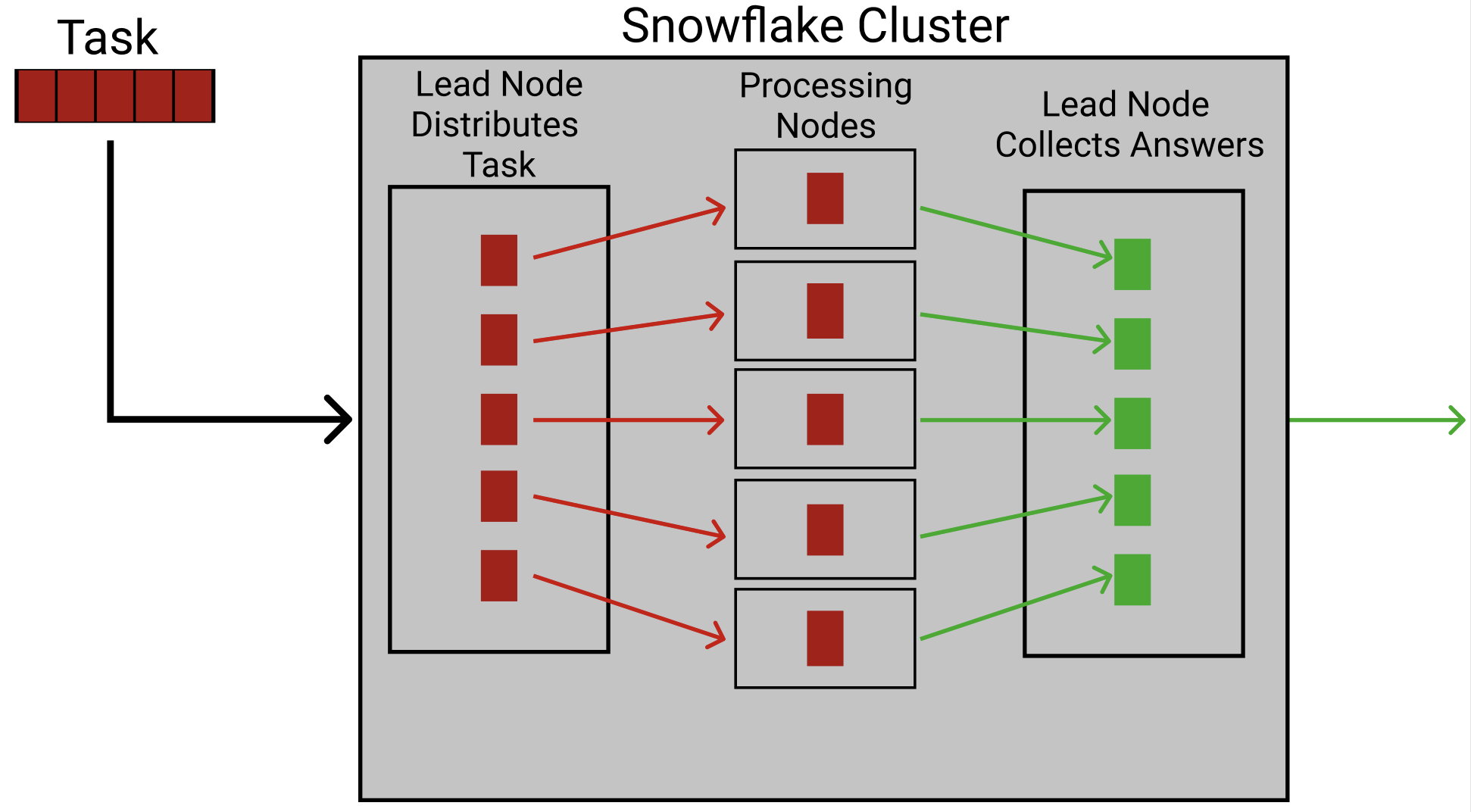
Since the data is stored in S3, snowflake will have slightly longer initial query times. This will speed up as the data warehouse is used however due to caching and updated statistics.
Snowflake’s Architecture
Snowflake has a specialized architecture that is divided into three layers: storage, compute, and services.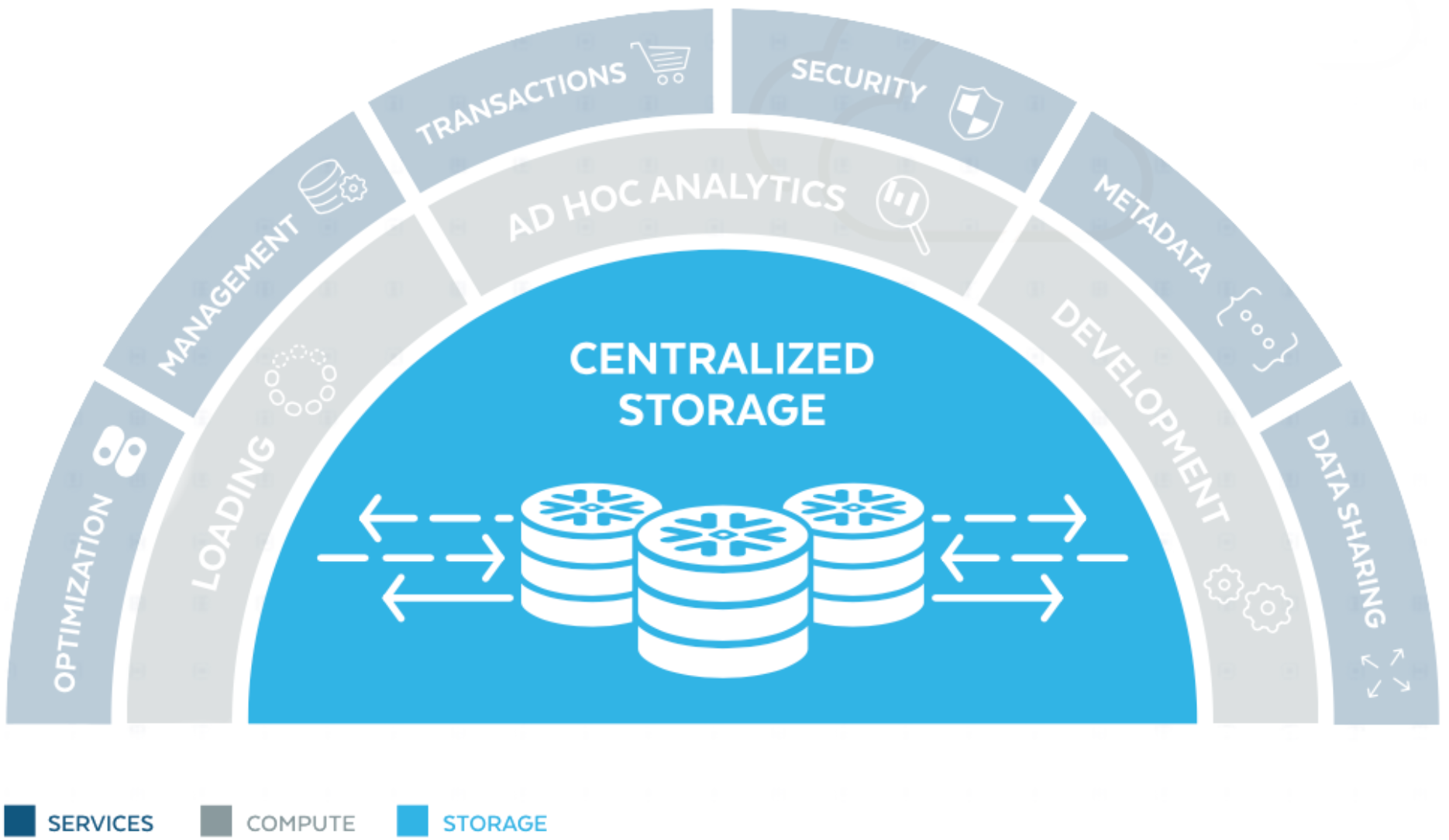
The Storage Layer:
- Elasticity: As mentioned before, storage is separated from the compute later. This allows for independent scaling of storage size and computer resources.
- Fully Managed: Snowflake data warehouses optimizations are fully managed by snowflake. Indexing, Views, and other optimization techniques are all managed by snowflake. The consumer can focus on using the data rather than structuring it.
- Micro-partitions: One optimization that Snowflake uses is micro-partitioning. This means that snowflake will set many small partitions on the data, which are then column stored and encrypted.
- Pruning: Micro-partitions increase efficiency through pruning. Pruning is done by storing data on each micro-partition and then, when a certain massive table needs to be searched, entire blocks of rows can be ignored based on the micro-partitions. This means that only pages which contain results will be read.
The Compute Layer:
- Caching: Snowflake will temporarily cache results from the storage layer in the compute layer. This will allow similar queries to run much faster once the database has been “warmed up.”
- ACID Compliance: Snowflake is ACID compliant. This means that it follows a set of standards to ensure that their databases have:
- Atomicity: If a part of a transaction fails, the whole transaction fails.
- Consistency: Data can not be written to the database if it breaks the databases’ rules.
- Isolation: Multiple Transaction blocks can not interfere with each other and be run concurrently.
- Durability: Ensures that data from completed transactions will not be lost in transmission.
The Services Layer:
- DML and DDL: There are 4 sub-languages in SQL:
- Data Definition Language (DDL): DDL is the sub-language that handles defining and describing structures in sql.
- Common Examples of DDL Commands: CREATE, RENAME, ALTER.
- Data Manipulation Language (DML): DML handles manipulating data in structures defined by DDL.
- Common Examples of DML Commands: SELECT, INSERT, DELETE.
- Data Control Language (DCL): DCL handles controlling access and privileges.
- Common Examples of DCL Commands: GRANT, REVOKE.
- Transaction Control Language (TCL): TCL handles control of transaction blocks.
- Common Examples of TCL Commands: START, ROLLBACK.
- Data Definition Language (DDL): DDL is the sub-language that handles defining and describing structures in sql.
Of these 4 sub-languages, Snowflake adds DDL and DML functions at the service layer. DCL and TCL are mostly handled by through the Snowflake GUI or automatically.
- Meta-data: Snowflake controls how meta-data is stored through the services layer, allowing it to be used to create micro-partitions and further optimizing the structure of the database.
- Security: Security is handled at the security layer. Snowflake does many things to increase security including: multi-factor authentication, encryption (at rest or in transit).
How is it Priced?
Snowflake has a variety of factors that impact the price of using their data warehouse. The first is what type of data you store.
Warehouse Type
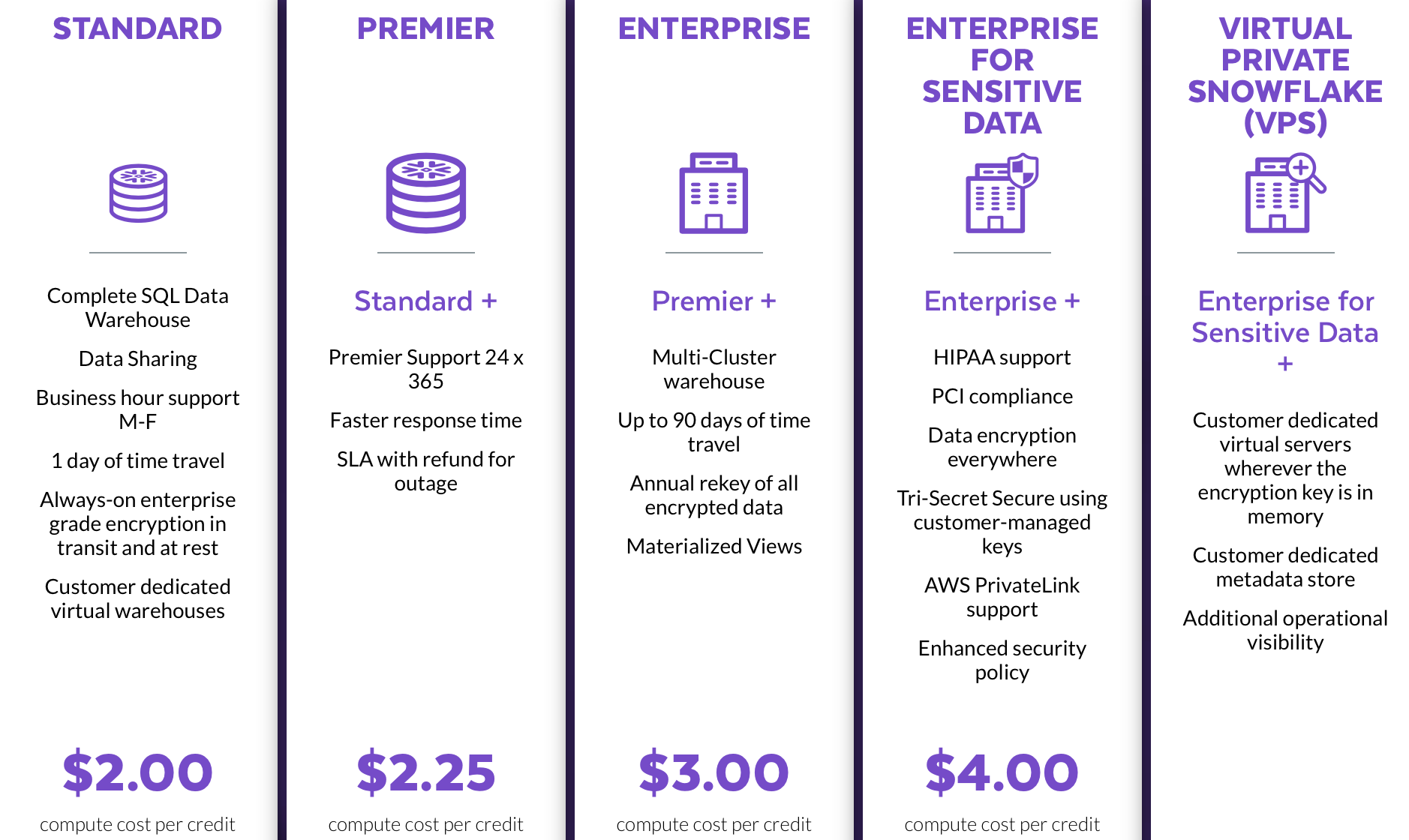
These different tiers decide what level of security, speed, and support are needed. They have corresponding costs as well. The basic package costs $2.00 per credit used. Credits are how snowflake measures the computations done.
Warehouse Size
While many data warehouse companies have a cost based on the maximum processing power that your database might need, snowflake is priced based on the amount of processing that is used. When you turn on your database, you can set what amount of processing power you want. The size of the warehouse can range from X-Small to 3X-Large. These sizes directly relate to how much computational power you can access and correspondingly how expensive the warehouse is. Here is a table from the snowflake documentation regarding the costs of three different sizes:
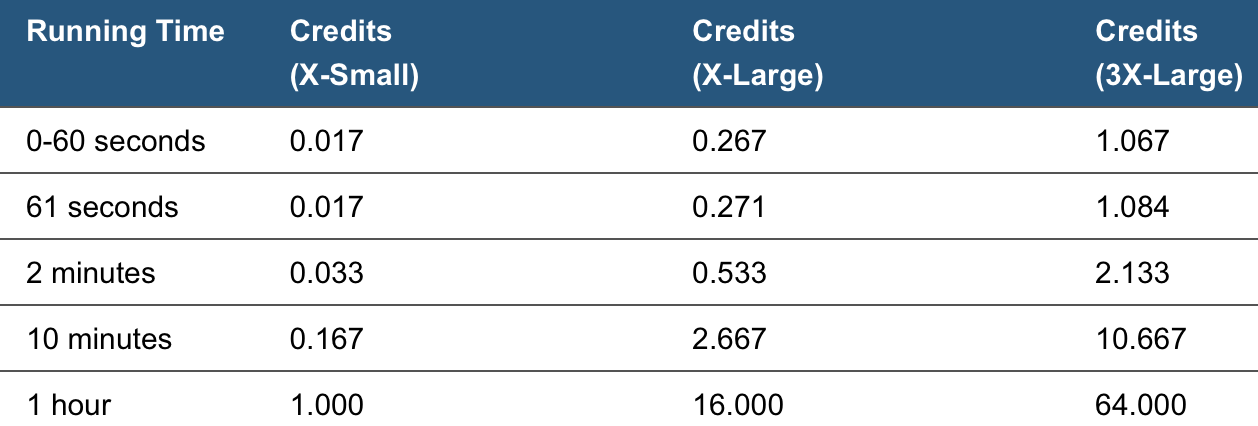
(Full list of sizes: X-Small, Small, Medium, Large, X-Large, 2X-Large, 3X-Large)
As the table shows the cost (in credits) is based on the size of the warehouse and the amount of time it is run for. For example, if you run a medium data warehouse, but need to run some intense queries for an hour, you can upgrade to a X-Large box for an hour. You can set this upgrade to automatically revert to medium after an hour as well to ensure you only pay for what you need.
Another Important detail about snowflake that we can determine from the table above is that snowflake has near linear scalability. An X-small warehouse costs 1 credit/hour (Note: this is per cluster. Multi-cluster warehouses will be charged based on the number of clusters). This price doubles for each tier that the warehouse goes up, as does the computational power.
Snowflake is designed for ease-of-use and easy hands-off optimization. Perhaps the best feature of snowflake is how easy it is to use. It is very simple once acclimated to, and can save you or your staff a lot of time and hardship handling technical details that even other RDBMS will not. As such it is a great tool for optimizing your database and optimizing your time.
Summary
- Snowflake is a RDBMS designed for OLAP usage
- Uses Amazon S3 for storage
- Separated storage leads to increased initial query times, but much better elasticity.
- Has near linear scaling in compute time (E.g. 2x the compute power = ½ the time)
- Has Architecture built for high speed under high load
- Extremely flexible pricing.
- Pricing by second used.
- Scheduled downgrading
- Tiers of data storage
- Linear pricing (2x the compute power = 2x the price)
Resources:
https://aptitive.com/blog/what-is-snowflake-and-how-is-it-different/
https://www.lifewire.com/the-acid-model-1019731
https://www.w3schools.in/dbms/database-languages/
https://www.youtube.com/embed/Qzge2Mt84rs?autoplay=1
Written by:
Matthew Layne
Reviewed by:
Matt David