Optimization with EXPLAIN ANALYZE
Last modified: July 17, 2019
Querying postgres databases, when done properly, can result in extremely efficient results and provide powerful insights. Sometimes however, queries are written in less than optimal ways, causing slow response times. Because of this, it is important to be able to analyze how queries execute and find the most optimized ways to run them.
One method for optimizing queries is to examine the query plan to see how a query is executing and adjust the query to be more efficient. Using the query plan can provide many insights into why a query is running inefficiently.
Explain and Explain Analyze
In postgreSQL, the query plan can be examined using the EXPLAIN command:
EXPLAIN SELECT seqid FROM traffic WHERE serial_id<21;

This command shows the generated query plan but does not run the query. In order to see the results of actually executing the query, you can use the EXPLAIN ANALYZE command:
EXPLAIN ANALYZE SELECT seqid FROM traffic WHERE serial_id<21;

Warning: Adding ANALYZE to EXPLAIN will both run the query and provide statistics. This means that if you use EXPLAIN ANALYZE on a DROP command (Such as EXPLAIN ANALYZE DROP TABLE table), the specified values will be dropped after the query executes.
The Data Used
The data that is being used to demonstrate optimization is a table of data regarding traffic violations which can be found here. It was imported from the csv file available for download and altered to have a SERIAL row named serial_id. The details of the table are shown here:
\d+ traffic
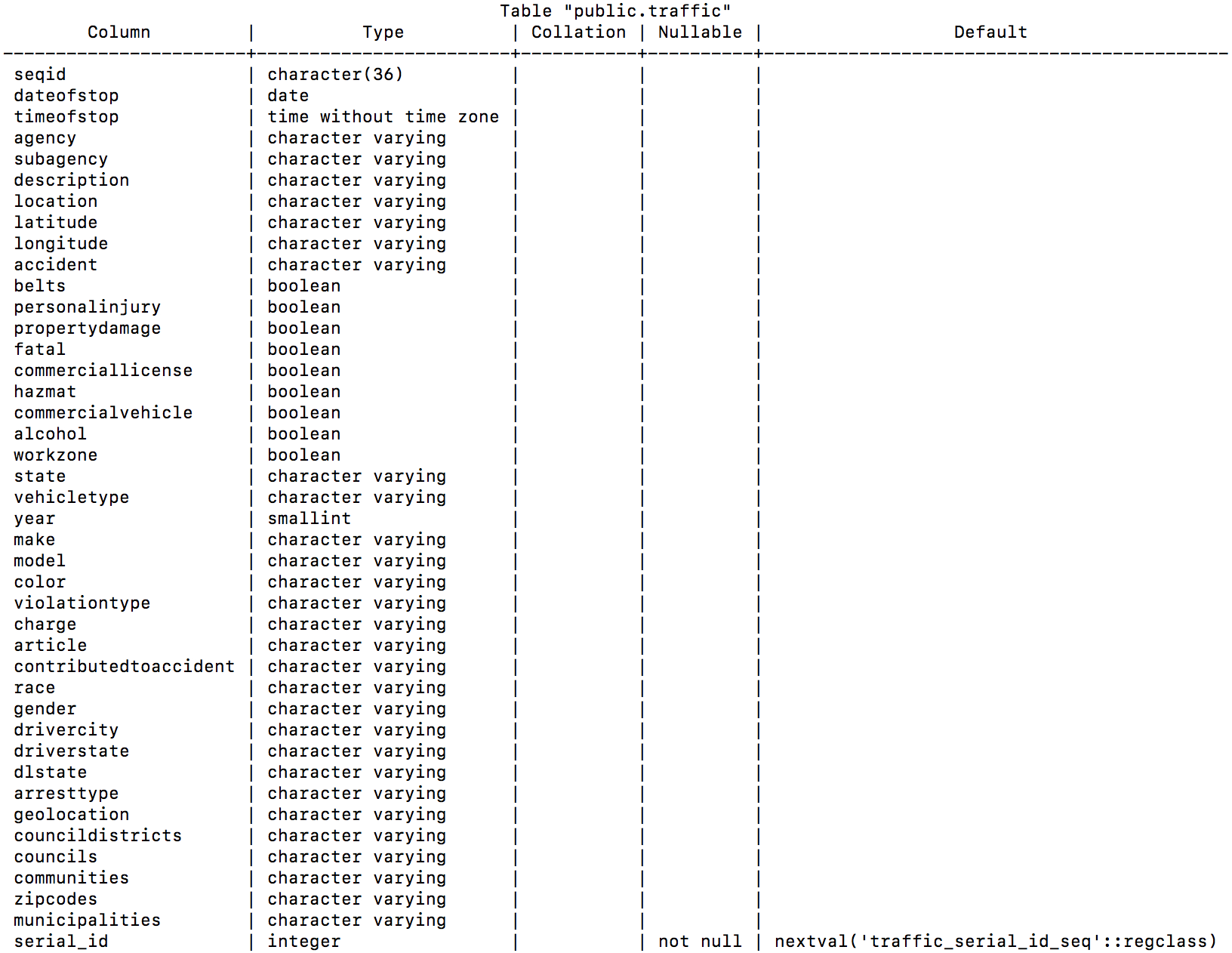
Indexes
Indexes are vital to efficiency in SQL. They can dramatically improve query speed because it changes the query plan to a much faster method of search. It is important to use them for heavily queried columns.
For example, an index on the serial_id column in the sample data can make a large difference in execution time. Before adding an index, executing the following query would take up to 13 seconds as shown below:
EXPLAIN ANALYZE SELECT * FROM traffic WHERE serial_id = 1;

13 seconds to return a single row on a database of this size is definitely a suboptimal result. In the query plan we can see that the query is running a parallel sequential scan on the entire table which is inefficient. This operation has a high start up time (1000ms) and execution time (13024ms).
A parallel sequential scan can be avoided by creating an index and analyzing it as shown:
CREATE INDEX idx_serial_id ON traffic(serial_id);
ANALYZE;
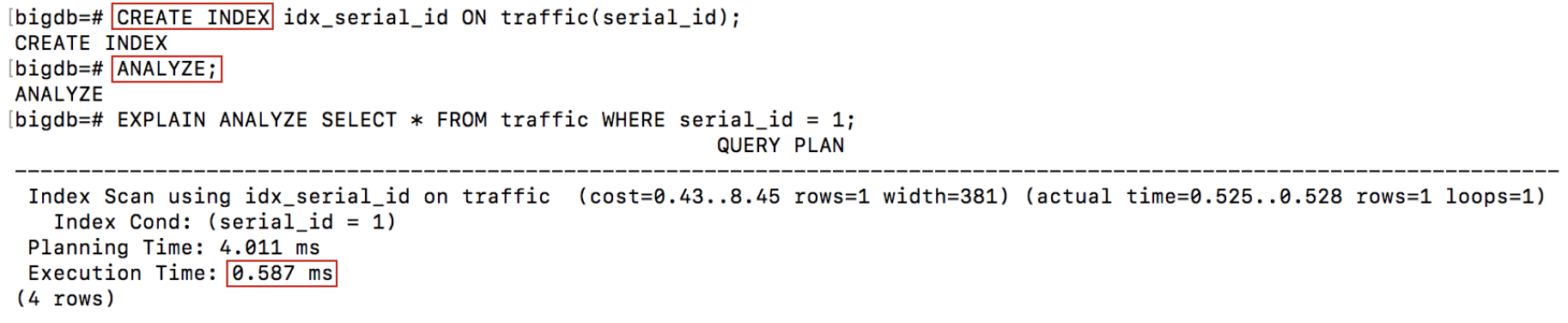
This shows that when using an index, the execution time drops from 13024.774 ms to 0.587 ms (that is a 99.99549% decrease in time). This is a dramatic decrease in execution time. The planning time does rise by 3.72 ms because the query planner needs to access the index and decide if using it would be efficient before it can start the execution. However the rise in planning time is negligible compared to the change in execution time.
Not all indexes will have the same amount of impact on queries. It is important to use explain analyze before and after implementing an Index to see what the impact was. Read Blake Barnhill’s article on indexing for more information.
Indexes are not always the answer. There will be times when a sequential scan is better than an index scan. This is the case for small tables, large data types, or tables that already have enough indexes to the specified query.
Partial Indexes
Sometimes it is best to use a partial index as opposed to a full index. A partial index is an index that stores ordered data on the results of a query rather than a column. Partial indexes are best for when you want a specific filter to operate quickly. For example, in this table, there are many types of vehicles that are recorded:
SELECT DISTINCT vehicletype FROM traffic
GROUP BY vehicletype;
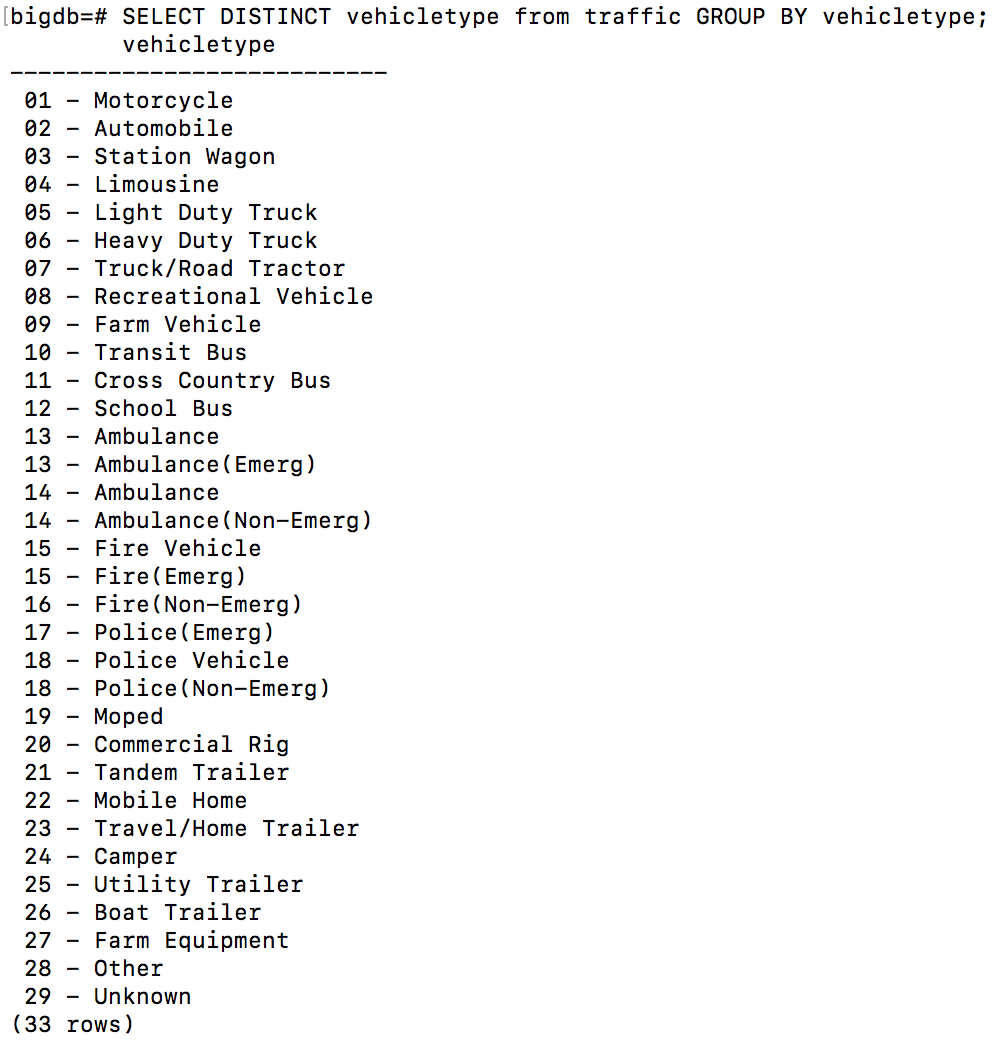
Many studies are done on motorcycle safety. For these studies, it would be wise to use a partial index on only motorcycles as opposed to an index which also includes unneeded information about other vehicle types. To create a partial index that only indexes rows involving motorcycles, the following query can be run:
CREATE INDEX idx_motorcycle ON traffic(vehicletype)
WHERE vehicle = '01 - Motorcycle';
ANALYZE;

This index will only store data relating to motorcycle violations, which will be much faster to search through than searching through the entire table.
Here are a few final tips about indexing:
- Remember to ANALYZE: it is important to run ANALYZE; after creating an index in order to update the statistics on the index. This lets the query planner make the most informed decision on when to use an index)
- Remember to VACUUM: It is important to run VACUUM ANALYZE after significant modifications to the table. This command will clean up the index’s statistics, throwing away old values and adding new values. This command will run automatically periodically, however it is useful to run this command after heavy modifications for quicker results.
- Make sure your query can use the index: avoid using Regex patterns with a wild card at the beginning such as LIKE ‘%[pattern]%’ this makes the query planner unable to use an index. You can use Regex patterns with wildcards at the end such as LIKE ‘[pattern]%’.
Data Types
Another important aspect of efficiency is the data types being used. Data types can have a large impact on performance.
Different data types can have drastically different storage sizes as shown by this table from the postgreSQL documentation on numeric types:
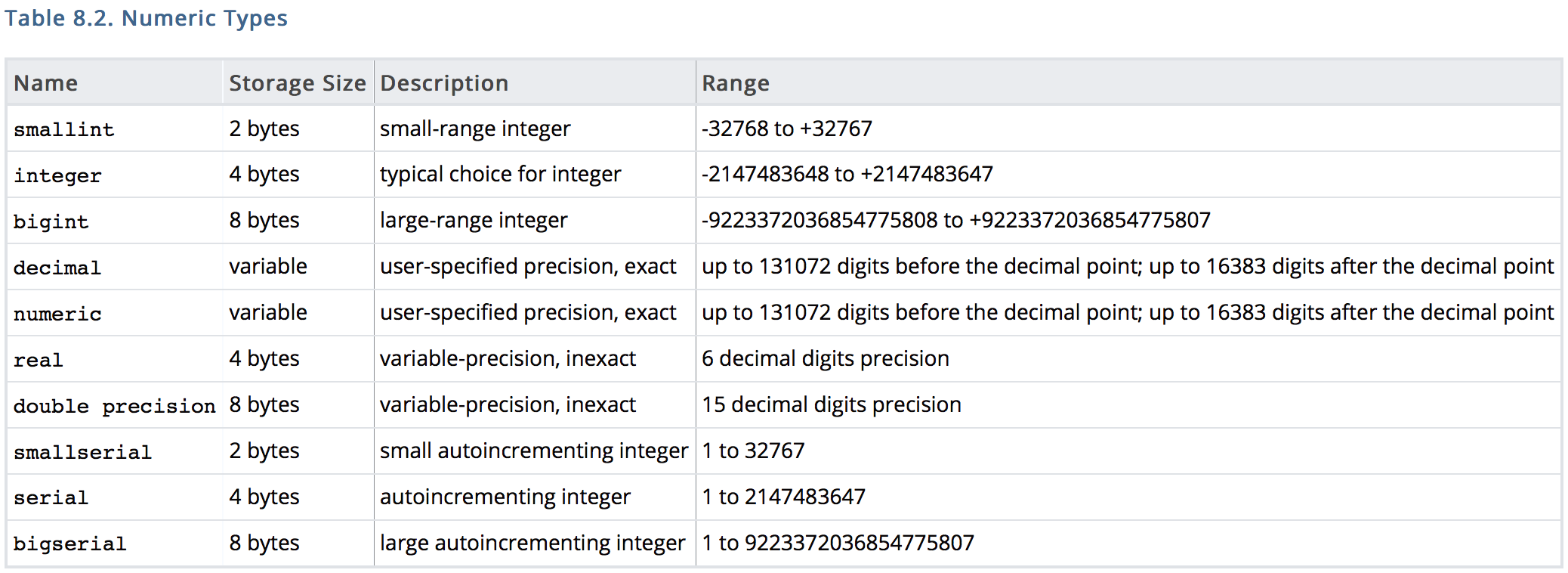
The dataset of traffic violations contains 1,521,919 rows in it (found using the COUNT aggregation). We need to consider the data type that requires the least amount of space that can store the data we want. We added a serial column to the data, which starts at 0 and increments by one each row. Since the data is 1,521,919 rows long we need a data type that can store at least that amount of data:
- smallserial is the best choice If the numbers of rows is under 32768 rows.
- serial is the best choice if the number of rows is more than small serial’s max or less than bigserials minimum.
- bigserial is the appropriate choice if there are more than 2,147,483,647 rows.
1,521,919 is greater than the smallserial limit (32,768) and less than the limit for serial (2,147,483,647), so serial should be used.
If we chose bigserial for the column, it would use twice the amount of memory needed to store each value because every value that is bigserial is stored as 8 bytes instead of 4 bytes for serial. While this is not terribly significant for very small tables on tables at the size of traffic or larger, this can make a large difference. In the traffic data set this would be an extra 6,087,676 bytes (6MB). While this is not too significant, it does impact efficiency of scans and inserts. The same principle applies to larger data types as well such as char(n), text data types, date/time types etc.
An example of this is, if a copy of traffic is created where serial is replaced with bigserial, then scan times rise. We can see this by comparing EXPLAIN ANALYZE results:
Results from Original Table:
EXPLAIN ANALYZE SELECT COUNT(*) FROM traffic;

Results from Copy:
EXPLAIN ANALYZE SELECT COUNT(*) FROM traffic2;

As we can see from the images above, the time to aggregate on the original table is 197 ms or 0.2 seconds. The time to aggregate on the inefficient copy is 1139 ms or 1.1 seconds (5.5 times slower). This example clearly shows that data types can make a large impact on efficiency.
Summary
- EXPLAIN ANALYZE is a way to see exactly how your query is performing.
- Indexes
- Best when created on unique ordered values
- Remember to ANALYZE after creating
- Remember to VACUUM ANALYZE
- Remember to write queries so that indexes can be used (e.g. use: LIKE ‘string%’ Don’t use: LIKE ‘%string%’)
- Partial Indexes
- Can be used for frequently queried subsections of a table
- Data Types
- Ensure that the smallest data type is used
- Be careful of this on tables with high throughput. Tables may grow past the data type’s size which will cause an error.
- Ensure that the smallest data type is used
References:
- https://thoughtbot.com/blog/postgresql-performance-considerations
- https://statsbot.co/blog/postgresql-query-optimization/
- https://www.sentryone.com/white-papers/data-type-choice-affects-database-performance
Written by:
Matthew Layne
Reviewed by:
Matt David
,
Blake Barnhill