Partial Indexes
Last modified: July 17, 2019
Partial indexes store information on the results of a query, rather than on a whole column which is what a traditional index does. This can speed up queries significantly compared to a traditional Index if the query targets the set of rows the partial index was created for.
Creating indexes is a common practice to optimize data warehouses, as explored in this article on traditional indexing. Partial Indexes are less discussed but should be incorporated along with traditional indexes into any optimization strategy due to their dramatic performance effects.
Basic Partial Index
A partial index can be as simple as an index that stores data on a subsection of a column. Take for example data.gov’s dataset on traffic violations in Montgomery County, MD. This table has many columns that could benefit from partial indexing. Columns that have many distinct groups in them are good for partial indexes as there is a large amount of data in the column. This is because columns like this are often filtered for one particular group.
One example of this is the column dlstate (the state that the driver has a driver’s license from). There are 71 distinct values (Includes out of country plates like QC for Quebec and includes XX for no plate) in the database for this column. Say you are studying how many Virginia driver’s are involved in Montgomery County traffic violations.
We are going to be filtering all our queries to where dlstate = “VA” so applying a partial index on the dlstate state column where dlstate = “VA” will make subsequent queries much faster. For this example we will focus on Virginia:
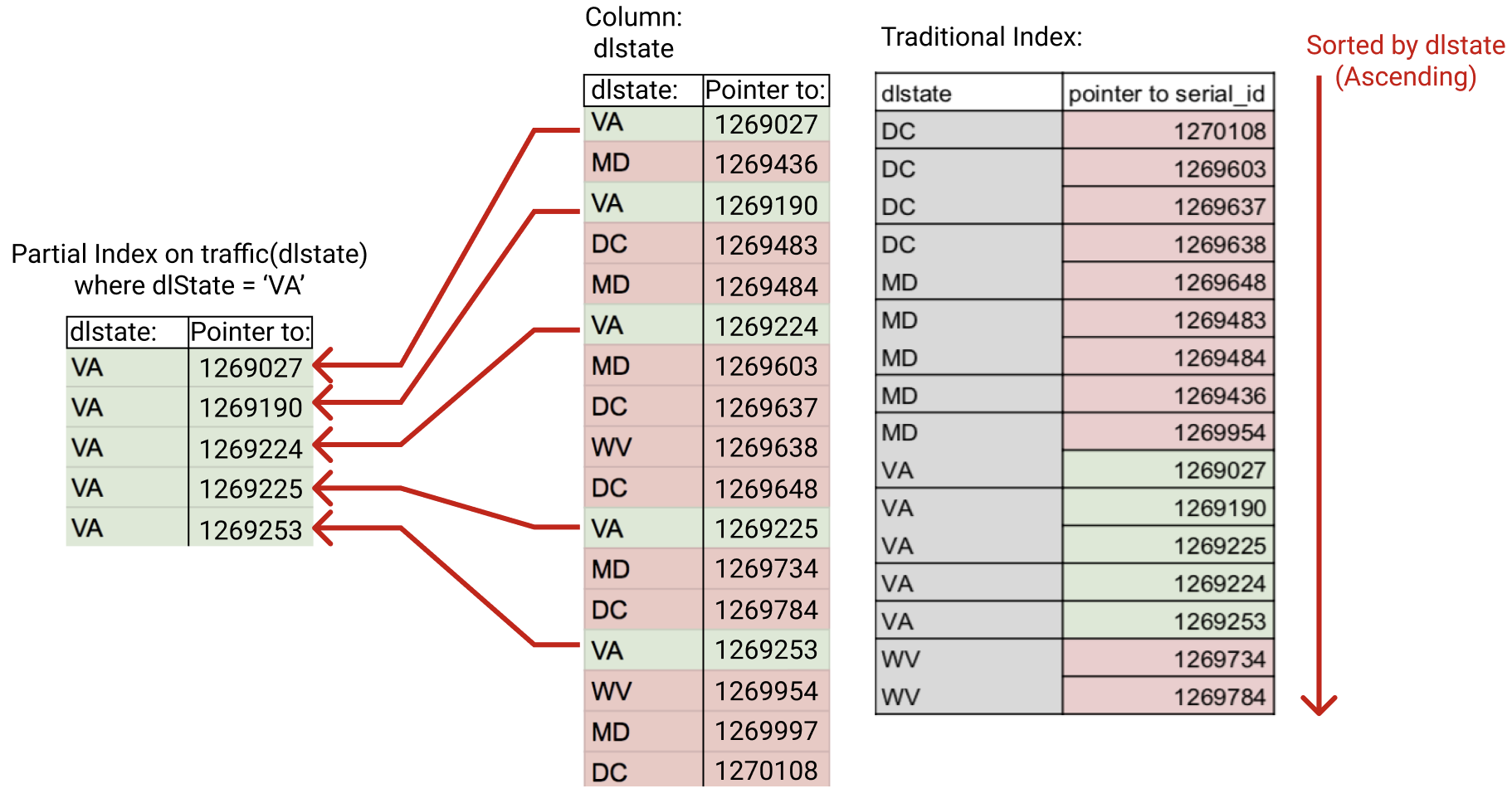
The command for creating a Partial Index is the same command for creating a traditional index with an additional WHERE filter at the end:
CREATE INDEX idx_dlstate_va ON traffic (dlstate) WHERE dlstate='VA';
ANALYZE;

Let’s now look at querying a sample of the data to see why Partial Indexing is much faster than querying the full table or an indexed version of the table.
Lets use a subset of the data and run the following query:
SELECT COUNT *
FROM traffic
WHERE dlstate='VA';
- Partial Index only has to move through rows where dlstate = VA.
- No index has to move through every row to find each place where dlstate = VA.
- Traditional index has the data sorted on dlstate but still has to traverse the b-tree to find where the rows where dlstate = VA are.
Remember to ANALYZE; after creating an index. ANALYZE; will gather statistics on the index so that the query planner can determine which index to use and how best to use it.
NOTE: Indexing will lock out writes to the table until it is done by default. To avoid this, create the index with the CONCURRENTLY parameter:
CREATE INDEX CONCURRENTLY [index name]
ON [table name (column name(s))] [WHERE [Filter]];
Time Comparisons
Now that the index has been created, and we have an understanding as to how the different types of indexes will be traversed let’s compare the query times where there is no index, a full index, and a partial index on the full data set:
No Index
- The speed of running a COUNT aggregation where the dlstate=’VA’ with a No Index is:
EXPLAIN ANALYZE SELECT COUNT(*)
FROM traffic WHERE dlstate='VA';

Speed: 1.79 sec or 1784 ms
With Traditional Index
- The speed of running a COUNT aggregation where the dlstate=’VA’ with a Traditional Index is:
EXPLAIN ANALYZE SELECT COUNT(*)
FROM traffic WHERE dlstate='VA';

Speed: 0.06 sec or 59.7 ms
With Partial Index
- The speed of running a COUNT aggregation where the dlstate=’VA’ with a Partial Index is:
EXPLAIN ANALYZE SELECT COUNT(*)
FROM traffic WHERE dlstate='VA';

Speed: 0.02 sec or 17.8 ms
Speed Comparison:

As this table shows that, while adding an index of either variety is a significant improvement, a partial index is roughly 3.5 times faster than a traditional index in this situation.
Advanced Partial Indexes
Partial indexes can become more advanced.
Like Traditional indexes:
- Can be Multi-column
- Can use Different structures
- E.g. B-tree, GIN, BRIN, GiST, etc.
Unique to Partial Indexes
- Can use complicated filters
- Smaller storage cost
- More Specific than Traditional Index
Complicated Filters
It is important to balance how specific the partial index with the frequency of queries that can use it. If the partial index is too specific, it will not be used often and simply be a waste of memory.
For example, a partial index could be created on a column with multiple filters such as the column ‘arresttype’ where the incident takes place from 4-4:30AM and zipcodes=’12’:

This would significantly speed up some queries, however this partial index is so specific it may never be used more than a few times.
Sometimes however, if a specific set of filters are used a lot it can dramatically increase performance. This is what makes partial indexes so powerful. If there are a large number of queries regarding specific times between 9am-5pm, we can create an index on serial_id for these times.

This new index will make filtering by times between 9am and 5pm much quicker. This includes times inside this range as well such as 12:00-1:00 pm.
Before Index:

After Index:

Here the execution time drops from 5013 ms to 247 ms (~20x faster with index) which shows that partial indexes can save time.
Partial Indexes are also usually less memory intensive than traditional indexes:

The traditional version of the index is 3 times the size of the partial index. The trade off here is that the traditional index can improve a wide range of queries where as the partial index is more specific, but also faster.
Summary:
- Partial indexes only store information specified by a filter
- Partial indexes can be very specific
- This can be good, but make sure to balance practically and memory size. Too specific an index becomes unusable.
- Partial indexes save space compared to traditional indexes
References:
Written by:
Matthew Layne
Reviewed by:
Matt David
,
Blake Barnhill