Data Warehouse Maintenance
Last modified: October 30, 2019
Now that you’ve setup a Data Warehouse, the next and ongoing step is maintenance. This involves making sure the Data Warehouse objects; columns, tables, views, and schemas are accurate and up-to-date. Maintaining your Data Warehouse is integral for users in your organization to easily and accurately gain insights into your data. If it is not maintained people will query the wrong data and get conflicting results.
As a company’s Data Warehouse ages:
- New Metrics need to be tracked
- Some old Metrics are no longer needed
- You will need to grant and remove permissions (more than you’d think)
- Modeling will become un-optimized
These inevitable problems make it difficult for your company to conduct analyses. To prevent these issues, you’ll need a data engineer familiar with the Data Warehouse, and how users are querying the source. This article will go in-depth on these issues and how to address them with routine maintenance.
Track New Metrics
Why do new metrics matter?
The way we need to measure our business will change over time. We will launch new products, look into different user behaviors, or try to create a predictive model. We need to track new metrics for these different efforts. Sometimes this means creating a new calculated field or a new column, view, or table.
We may add a new field to track our customer information in Salesforce that is inline with our new company objectives, say, tracking account activities through the services we provide. From here, we can see what services are most popular with our customers, then, offer special promotions on these services during seasonal trends where we see a fall in purchases in order to increase sales.
Why do new metrics cause issues in a Data Warehouse?
When engineers or analysts create new tables, columns, or views to track metrics they do not always follow the naming convention set out for the Data Warehouse. This makes interpretation difficult by an analyst unfamiliar with the new metrics.
This can also create duplicate work – say you created a view for your support team but the view along with the pertinent information inside it do not distinguish exactly what this view is for. Users looking to query this view may not know it exists, so they may recreate this view.
How to add new metrics correctly.
When adding new metrics we need to consider:
- How to add to the Schema
- Backfilling data
- Naming Conventions
How to add to the Schema
Do we only need to add the data to an existing table or should we add to a view or create a whole new view? Let’s review what reasons we would do each:
Existing Table
- The new metric can be understood and queried easily without complex joins or being aggregated.
Existing View*
- A view that exists that is relevant to the new metric.
- That view is aggregated in a way that fits this data and its dependent metrics.
- Complex join paths would make it difficult for people to query the new data accurately without the view.
New View*
- No view that exists that is relevant to the new metric.
- No view that is relevant is aggregated in a way that fits how this metric should be aggregated without the view.
- Complex join paths would make it difficult for people to query the new metric accurately.
*Typically it will be added to an existing table as well but it will be queried from the View
Backfilling Data
It is advisable to backfill data whenever we can determine what the values should be.
In a dimension table we might be able to determine the value based off of other columns or there is an obvious default value to plug in. If we are not able to determine or have no obvious default value leave the value as null. However, do consider the impact of nulls, such as in aggregation. If this will impact your query try determining a stand in value to indicate you could not backfill it.
In a measures table the same principles hold, so if it can be determined backfill it. Since measures are more often aggregated the impact of nulls can be even greater. The other negative of nulls in a measures table that has time-based data is that it limits your analysis to when you added the new column. Sometimes this issue can be overcome by bringing in data from previous data sources or by inputting values based on overall statistics or dimensions of each row.
Naming Conventions
We also need to ensure these views, tables and columns follow the Data Warehouse’s naming conventions. At Chartio, we follow a naming convention when adding new metrics or updating metrics and making sure the name captures the purpose of the updated metrics (Naming Convention and Style Guide). We recommend publishing your style guide and distributing it among your employees as familiarity with the process keeps the naming convention intact.
Deprecate Old Metrics
Why do old metrics matter?
Metrics may become inaccurate or no longer worth analyzing. We want to prevent that data from being queried so others do reach false conclusions.
Why do old metrics issues happen?
As companies grow the tools they use to get and move data change. This leads to multiple places where the same type of data can be queried. Since the analyst might not be aware of which source to use they may query the wrong data.
Also business objectives may change. This can affect what data is appropriate for analysis as well. Features or products may have been deprecated as a result and therefore their associated metrics might be misleading if the analyst was unaware of this.
How to deprecate old metrics correctly?
If you’re not going to remove columns, tables, or views from user’s access right away, we recommend updating the names for these objects to _deprecated, or, _do_not_use. This makes it clear when browsing or querying that they should not be used.
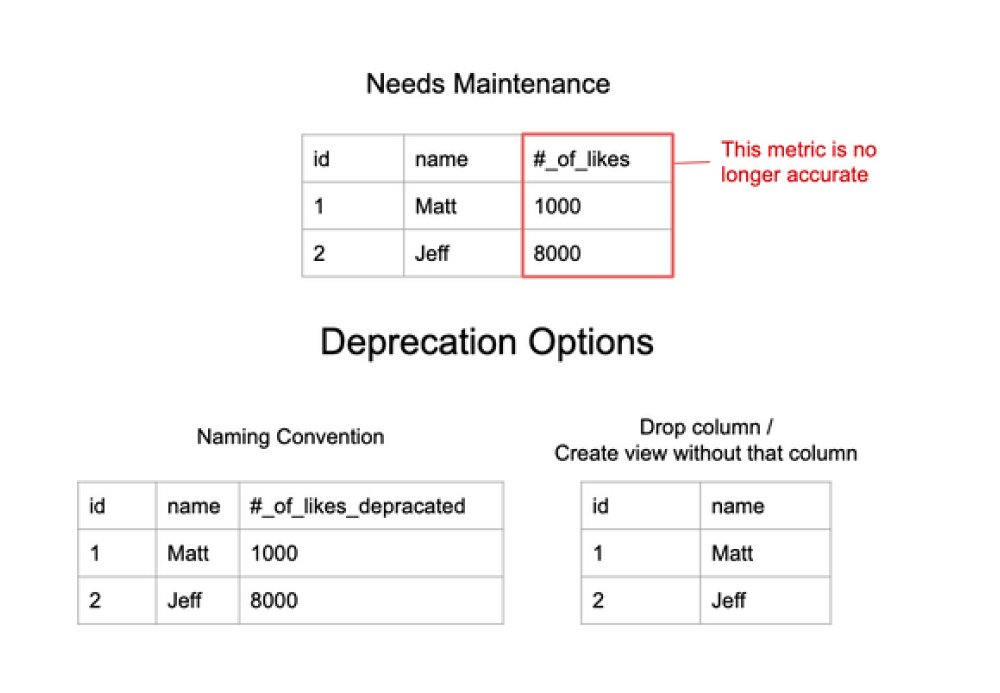
This style for old metrics should be incorporated into your company’s naming convention style guide. It’s also worth letting users know that these metrics are no longer useful through email or with your BI Tool so they’re not caught off guard. Again, naming conventions play an integral role in how we keep users from querying data warehouse objects incorrectly.
Handle Permissions
Why do permissions matter?
Not being granted access to the data you need completely halts analysis. Similarly, not removing someone’s access can be a legal liability. Having the right permissions is a line that should be carefully considered, but caution should be taken to ensure that it doesn’t become a bottleneck.
Consider a scenario where you have users working on multiple BigQuery projects and you’re worried about query costs. In order to prevent users from abusing queries and raising the cost, you’ll want to create a custom quota. As the BigQuery documentation outlines, a custom quota will manage costs by specifying a limit on the amount of query data processed per day. This can be set at the project-level, or, at the user-level. This type of permissioning is aimed at price reduction, but we can also have permissionings aimed at keeping data intact, or, for privacy concerns.
Oracle offers the ability to recover a dropped table, but, some data warehouses do not have this ability. If you drop a table in PostgreSQL, you won’t be able to restore this table unless you restore from a backup. If you can’t restore from a backup, there will be no way to recover the dropped table. To avoid this, make sure the proper individuals have the right permissioning on the right Data Warehouse objects.
Why do permission issues happen?
Permission issues happen when the BI Tool or Data Warehouse access does not mirror employee status. This happens when:
- New employees need to query the Data Warehouse
- Employees change roles
- Employees leave
- Special permission
- Account sharing
When you hire analysts, or an individual’s role changes which requires more access to the Data Warehouse, you will want to make sure they have the appropriate permissions to analyze metrics in the warehouse. If they lack the proper permissions, this will create a barrier in completing their tasks. Or, if there are no restrictions in what objects they can access in place, those unfamiliar with the Data Warehouse might alter or drop an object.
When employees leave sometimes not all of their accounts are deactivated. You may turn off their email but this would not prevent them from logging into the BI Tool. Their account can remain active which is a security concern.
Sometimes an employee is granted special permission to temporarily gain access to more data. The problem occurs when their temporary access is not revoked after they no longer need it. Lastly, employees often share accounts to get the access they want for a particular analysis. This is a bad practice as it does not leave a trace as to who is looking at what data.
How to handle permissions correctly.
Making sure your BI Tools access levels mirror the employment status of your employees helps you track users and prevent security issues. The main priority of granting permission is to prevent users from being able to access sensitive information, or, from accidentally deleting data that can’t be recovered.
We recommend setting user permissions at a team level because as you scale up your usage and add more users, it’s easier to track. Tracking individuals in a small company is trivial since you know everyone by name and when new people are hired and when people leave. In large companies you don’t know the vast majority of the people you work with and do not know when their roles or employment status changes.
Sharing accounts is an unfortunate practice that you need to keep an eye on. Sharing accounts makes it impossible to hold users responsible to what action they’ve carried out. If there needs to be an answer as to why a user dropped a table or updated a column, you might have to ask multiple people to figure it out. This can also be a potential breach of an agreement you may have with your customer and their expectations of how you handle their data. We recommend giving each user a separate account. This ensures security compliance and accountability in the event of an error.
We recommend programmatically adding and removing users to avoid employees from being blocked and to ensure they do not maintain access to data they should not have. If you decide to manually add, remove, or change privileges for users, you’ll need to be vigilant in completely removing/updating the permissions.
Tuning to Optimize
Why does ongoing modeling matter?
The amount of data you have will grow as your business grows and your objectives change and you begin to track new metrics. As the data grows, you will need to consider if the way you designed the Data Warehouse objects; schemas, tables, views, and columns still makes sense based on the way users query it.
An indicative sign of needing to revisit Data Warehouse objects or when you should consider remodeling the objects is performance. Performance matters to users, if non-complex queries take too long to run they will stop querying data or start filing tickets to engineering.
Why do warehouses need ongoing optimization?
As your company grows the data that is queried changes too. New data, new analysts, and new business objectives will shift what data is being queried. The original structure of Data Warehouse objects may need to be reconfigured to optimize usage and performance based on how it is queried.
How to continually optimize your warehouse?
Different data warehouses will have options to check performance, but most offer ways to:
- Identify slow queries and add indexes
- Identify common queries and create views
Identify slow queries and add indexes
PostgreSQL has a “slow query” log that lets you set a threshold of an amount of time, if a query takes longer than this threshold a line is sent to the slow query log. From here, the data engineer can determine how to best optimize the most efficient way to run the query, such as, examining the query plan to see how a query is executing and adjust the query to be more efficient.
We can deploy the EXPLAIN command and the EXPLAIN ANALYZE command. The EXPLAIN command shows the generated query plan but does not run the query. To see the results of actually executing the query, you can use the EXPLAIN ANALYZE command. Based on the output, you can decide to create an index to speed up the query time. To learn more about indexing and the various types, read indexing.
Identify common queries and create views
In PostgreSQL you can use `pg_stat_statements` to group identical queries and find optimization opportunities. The `pg_stat_statements` directive stores queries that are run against your PostgreSQL instance. It saves the query, the execution time, the underlying reads and writes, and the variables. This information allows you to determine what type of data users want so you can optimize frequently used queries.
Creating a view can help users unfamiliar with the structure of the data warehouse by consolidating what they need to query to a single place. For example, you can grant users from a specific department access to a view that reflects all the departmental information they need to query.
In addition, you can get performance benefits if you materialize the view or create a new table. Most of the improvements here will be seen if the query is heavily filtered or if it is aggregated. Users can then query the materialized view or table. You can get an even bigger bump in performance if you add an index to this new materialized view or table.
To learn more about the pg_stat_statements, I recommend reading the following articles; The most useful Postgres extension: pg_stat_statements and pg_stat_statements: The Way I Like It.
Summary
A Single Source of Truth Data Warehouse is a worthwhile investment. However, without maintenance it will fall into disarray and lose its value.
- As metrics are added, make sure they’re named properly.
- As metrics are deemed no longer useful, make sure they’re removed to avoid confusion.
- As you vet your metrics and find that some need to be updated/pre-aggregated, make sure they’re named properly.
- Keeping user permissions appropriate and accurate will free up database admins to focus on important projects as well as avoid data being removed accidentally.
- Considering the restructuring of Data Warehouse objects will help create a suitable structure for analysis and complex querying along with cutting down performance cost.
- The worthwhile investment of a data engineer to perform said maintenance tasks will remove the bottleneck of incorrect analytics from a neglected warehouse.
References:
- Claire Carroll - Fishtown Analytics: Five principles that will keep your data warehouse organized
- Claire Carroll: The difference between users, groups, and roles on Postgres, Redshift and Snowflake
- Don Jones: Three data warehouse maintenance tips for DBAs
- BigQuery Documentation: Creating custom cost controls
- Stack Over Flow: Can I rollback a transaction I’ve already committed? (data loss)
- CYBERTEC: 3 Ways to Detect Slow Queries in PostgreSQL
- CYBERTEC: pg_stat_statements: The Way I Like It
- Citusdata: The most useful Postgres extension: pg_stat_statements
Written by:
Jaime Flores-Lovo
Reviewed by:
Matt David